Exploring Kappa and Lambda Architectures for Data Engineers
Written on
Introduction to Key Concepts
In this series, I will introduce several crucial concepts that aspiring Data Engineers should familiarize themselves with. Previously discussed topics include:
- Data Modeling
- Change Data Capture (CDC)
- Idempotency
- ETL vs. ELT
Additionally, I have produced two series focused on Python:
- Efficient Python
- Software Engineering with Python
The Kappa and Lambda architectures have emerged as significant frameworks for managing large-scale data processing. Each architecture provides effective solutions for both real-time and batch processing, enabling organizations to extract valuable insights from their datasets.
Lambda Architecture: Integrating Batch and Real-Time Processing
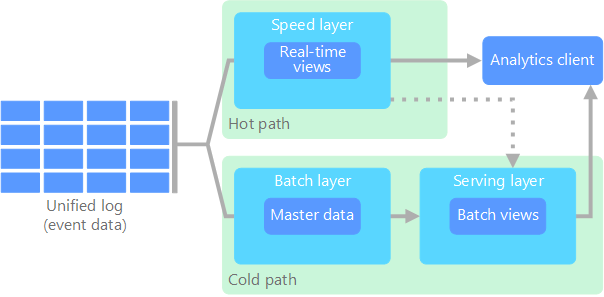
The Lambda architecture tackles the challenge of merging real-time and batch processing for big data tasks. It employs a hybrid model that utilizes both batch and streaming processes to deliver accurate, up-to-date insights.
At its core, the Lambda architecture is built upon the principle of immutable data. Incoming data is captured and stored in a manner that preserves an unalterable historical record. This architecture consists of three primary layers:
- Batch Layer: This layer processes significant amounts of historical data in batches. Data is collected from sources, transformed, and stored in a batch processing system like Apache Hadoop or Apache Spark, where it is indexed for querying.
- Speed Layer: The speed layer manages real-time data processing. It deals with incoming data streams almost instantaneously and generates incremental updates that are combined with the batch layer's results to provide a cohesive data view. Technologies like Apache Storm or Apache Flink are typically employed here.
- Serving Layer: This layer serves as the interface for querying and visualizing data. It merges outputs from both the batch and speed layers, offering a consistent data view. Common storage technologies include Apache HBase or Apache Cassandra.
The Lambda architecture boasts several advantages, such as fault tolerance through data replication and scalable processing since each layer can be independently scaled. Additionally, separating batch and real-time processing leads to efficient resource use, particularly for batch computations over larger time frames.
However, it also presents challenges, including the complexity of managing two distinct processing pipelines and ensuring data consistency across layers. Additionally, maintaining synchronization in the serving layer with updates from both sources adds to the system's complexity.
Video: Kappa Architecture | Data engineering system design questions - YouTube
The Kappa Architecture: Streamlining Real-Time Processing
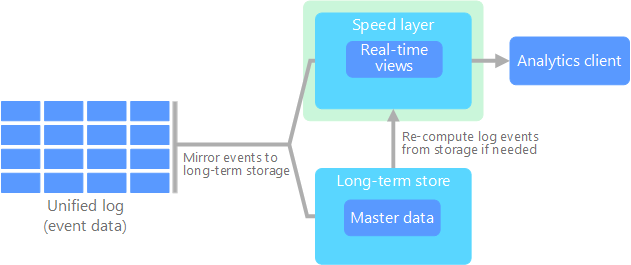
The Kappa architecture presents a streamlined alternative to the Lambda model by concentrating exclusively on stream processing. This approach embraces immutable data streams, removing the necessity for a separate batch layer.
In the Kappa framework, all data is processed as a continuous stream of events. This allows for real-time processing and near-instantaneous insights. The main components of the Kappa architecture include:
- Stream Ingestion: Data is constantly collected from various sources and stored in an event log, such as Apache Kafka, which serves as a durable, fault-tolerant storage mechanism, preserving the complete event history.
- Stream Processing: The stream processing layer retrieves data from the event log, performs real-time computations, and generates the required outputs. Technologies like Apache Kafka Streams or Apache Flink are often utilized for processing and analytics.
- Output Serving: The processed data is made available through various channels, such as real-time dashboards, APIs, or data sinks for further analysis.
The Kappa architecture offers numerous benefits, including reduced operational complexity by focusing solely on stream processing, low-latency processing, and simplified data consistency since there is no need to synchronize different layers.
However, potential challenges may arise, particularly regarding batch processing and historical analysis, as all data is processed in real-time. This limitation could complicate certain use cases requiring extensive historical data analysis. Moreover, the continuous nature of stream processing introduces dependencies on the performance and scalability of the streaming framework.
Choosing the Right Architecture: Key Considerations
When selecting between the Lambda and Kappa architectures, several factors should be evaluated:
- Data Characteristics: Assess the data's nature and processing needs. If both real-time and historical analysis are essential, the Lambda architecture may be more appropriate. Conversely, if real-time processing and low latency are the primary focus, Kappa might be the better choice.
- System Complexity: Consider the complexity of managing multiple processing pipelines in the Lambda architecture against the simplicity of a single stream processing pipeline in Kappa. Evaluate your organization’s resources and expertise regarding implementation and maintenance.
- Scalability and Performance: Examine the scalability requirements. Both architectures can scale horizontally, but technology choices and implementation specifics can influence performance.
- Data Consistency: Investigate the consistency needs of your application. The Lambda architecture includes mechanisms for consistency, while Kappa simplifies this aspect, though additional considerations for out-of-order events may be necessary.
- Operational Considerations: Review the operational aspects such as deployment, monitoring, and fault tolerance. Assess the availability of tools and community support for the chosen architecture.
In summary, both Kappa and Lambda architectures present powerful solutions for processing large data workloads. The Lambda model merges batch and real-time processing for a comprehensive data overview, while Kappa simplifies design with a focus on real-time processing for quick insights. By carefully evaluating the specific requirements of your data and application, you can select the architecture that best aligns with your goals and enables your organization to gain valuable insights from big data.
About Me
For more information and services, feel free to connect with me on:
- GitHub
- Medium
- My Data Courses (Udemy)
- Mentorship Program and Sessions
- Subscribe to my Newsletter
- Join Medium using my referral link
- My life in Germany
- YouTube
Video: Lambda Architecture | Data Engineer System Design Interview | Spark Interview Questions