Choosing the Ideal Machine Learning Algorithm for Your Needs
Written on
Chapter 1: Understanding Machine Learning Algorithms
When I embarked on my journey into data science and machine learning, I often sought out tutorials and resources to help me implement various algorithms. The internet is abundant with information on how to apply these algorithms, their workings, and their application to datasets.
However, I found myself grappling with the decision of which algorithm to use when it came time to work on my projects. A significant gap in many articles is the guidance on when to use a particular algorithm and how to determine the most appropriate one for your data. In this article, I will outline my approach to selecting the most suitable machine learning algorithm for a specific task.
Before diving in, let's first explore the different types of machine learning algorithms.
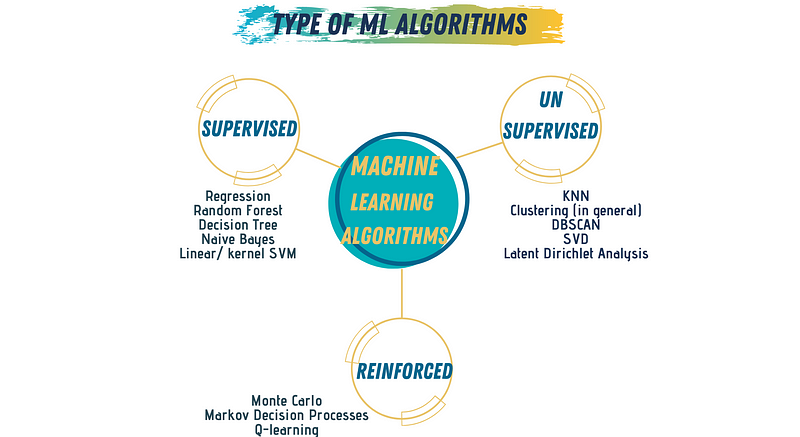
Types of Machine Learning Algorithms
Machine learning algorithms can generally be divided into three primary categories:
Supervised Learning
In this approach, the algorithm creates a mathematical model using labeled training data, which includes both inputs and outputs. Classification and regression algorithms fall under this category.
Unsupervised Learning
Here, the algorithm develops a model using data that contains only input features without any output labels. The models are trained to identify patterns within the data. Clustering and segmentation are prime examples of unsupervised learning algorithms.
Reinforcement Learning
In this method, the model learns to complete tasks by making a series of decisions and actions based on feedback from previous choices. Monte Carlo algorithms are an example of reinforcement learning.
Choosing the Right Algorithm
Now that you're familiar with the types of algorithms, the next question is determining when to apply each one. To address this, we need to consider four key aspects of the problem at hand:
The Data
Understanding your data is the foundational step in choosing an algorithm. Before considering various algorithms, familiarize yourself with your dataset. Visualizing the data can help identify patterns and behaviors, as well as its overall size.
Knowing critical information about your data will aid in making an informed initial choice. For instance, some algorithms perform better with larger datasets. For smaller training datasets, models with high bias and low variance typically outperform their low bias and high variance counterparts. As an example, Naïve Bayes is often more effective than kNN for smaller datasets.
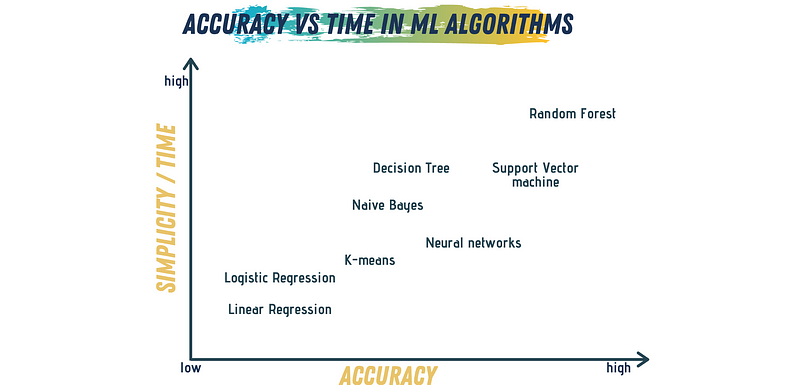
The Accuracy
After analyzing your data's characteristics, it's crucial to evaluate how important accuracy is for your specific problem. Accuracy refers to a model's capability to deliver predictions that closely align with the actual outcomes.
In some cases, a precise answer may not be necessary. If an approximation suffices, using a simpler model can significantly reduce training and processing times.
The Speed
Often, there's a trade-off between accuracy and speed when selecting an algorithm. Higher accuracy usually requires longer training and processing times. Simpler algorithms like Naïve Bayes, Linear regression, and Logistic regression are easier to implement and execute quickly. Conversely, more intricate algorithms such as SVM, Neural Networks, and Random Forests typically demand more processing time.
Consider which aspect is more valuable for your project: accuracy or speed? If speed is paramount, a simpler algorithm may be preferable. If accuracy takes precedence, a more complex model would be the better choice.
Features and Parameters
The parameters of your problem influence how the chosen algorithm will perform. These parameters may include error tolerance levels, iteration counts, and algorithm variants. The number of parameters often correlates with the time required to train and process your data.
It's important to note that a larger number of features can slow down certain algorithms, extending training times. For datasets with many features, an algorithm like SVM, which excels in high-dimensional spaces, is often the best choice.
Final Thoughts
Numerous factors influence the process of selecting an algorithm. Primarily, you can categorize your decision criteria into data-related and problem-related aspects.
Understanding the size, behavior, characteristics, and type of your data will provide a preliminary insight into which algorithm to consider. Once you have that foundation, various elements of your problem will guide you to a final decision.
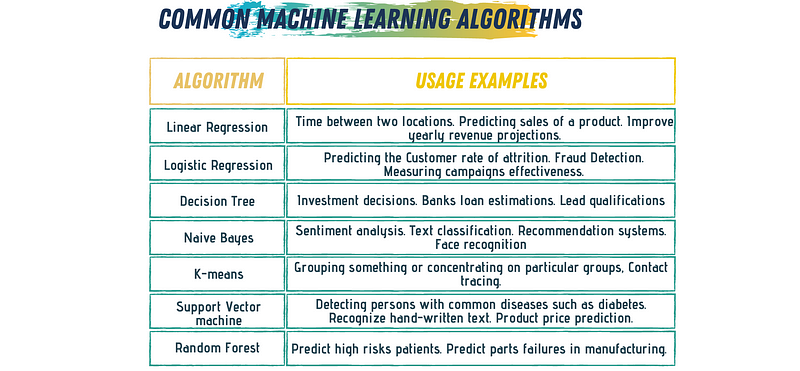
Ultimately, always remember two key principles: Better data leads to improved results compared to complex algorithms. If you can achieve similar outcomes with a simpler model, opt for simplicity. Moreover, you can enhance an algorithm's accuracy by investing more time in data processing and training. Your decision should reflect the priorities specific to your project.
Always be attentive to the story your data tells, while aligning with your project's objectives.
Chapter 2: Video Insights
The first video, "How do you select the right machine learning algorithm?" explores the critical considerations for choosing the appropriate algorithm based on project needs.
The second video, "Machine learning algorithms: choosing the correct algorithm for your problem," provides insights from Joakim Lehn on effectively selecting algorithms for various data challenges.