Unlocking the Power of SQL in Cognitive Neuroscience Research
Written on
Chapter 1: Introduction to SQL in Research
SQL, or Structured Query Language, serves as a vital tool for managing relational databases and manipulating data. Its significance in various industries is undeniable, particularly for those handling extensive and intricate databases. With SQL, researchers can swiftly query data, thanks to its declarative nature. This means that while users specify what they want, the underlying mechanics are handled seamlessly by the language. For those already familiar with imperative programming languages like Python, picking up SQL is generally straightforward. The groundwork has been laid by countless professionals, allowing us to focus on simply instructing the system on our data needs.
When I first encountered SQL, I underestimated its potential utility in my graduate studies in computational cognitive neuroscience. Although I recognized its industry relevance, I initially did not plan to integrate SQL into my academic work. However, upon further reflection, I realized that maintaining relational databases could greatly benefit my research endeavors.
Section 1.1: The Need for a Relational Database
My research centers on the cognitive neuroscience of aging, where I conduct brain imaging studies involving samples from younger adults (ages 18–29) and older adults (ages 65–79). Recruiting older participants can be particularly challenging due to the demanding nature of the studies, which often last several days and include lengthy MRI sessions. Consequently, the same older adults frequently participate in multiple studies within our lab. Although study designs vary, many foundational elements remain constant, indicating an unrecognized longitudinal study approach.
Despite the repeated involvement of the same participants, our lab lacked an efficient tracking system to monitor their study participation over time. Each research effort operated independently, which was a missed opportunity for longitudinal tracking. This realization prompted me to consider the transformative potential of a lab-wide relational database management system, enabling us to maintain participant data in one centralized location.
Subsection 1.1.1: Benefits of a Standardized System
Creating this database management system offers numerous advantages. For instance, my colleagues and I could perform insightful analyses, such as monitoring cognitive performance (e.g., memory) over time, helping us identify trends in cognitive decline among participants. Additionally, the system could streamline the administration of assessments. In scenarios where multiple studies occur simultaneously using the same neuropsychological battery, we could avoid repetitive testing to mitigate practice effects. Furthermore, the ability to integrate data from various studies would enhance research outcomes. For example, my imaging studies could correlate with behavioral measures from colleagues’ studies, enriching our understanding of cognitive processes. Overall, a relational database system could significantly elevate the impact of our research.
Chapter 2: Building the Database
Having outlined the advantages of developing a database, I will now share my approach to its creation. As a novice in relational database design, I welcome any constructive feedback. Before diving into the database construction, I utilized a diagramming tool, DBDiagram, to map out the database structure.
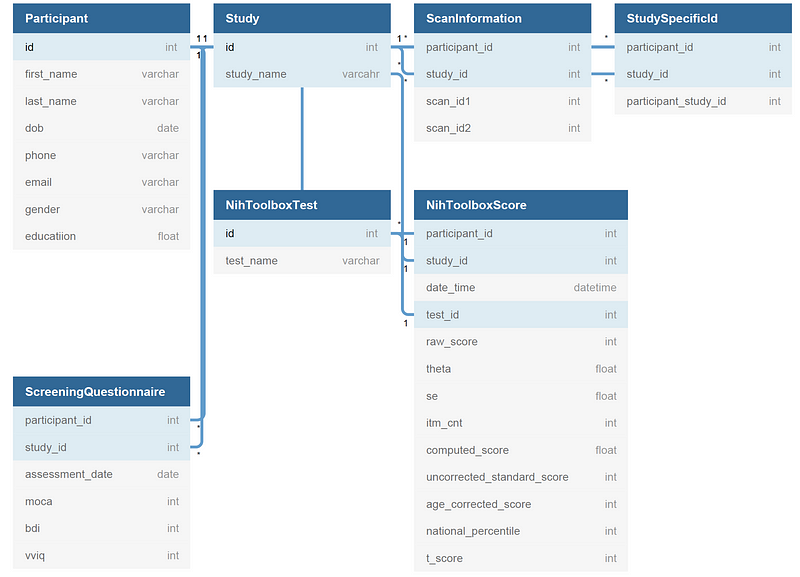
In essence, each participant is assigned a unique ID, and each study is also designated a unique ID. The NIH Toolbox serves as the neuropsychological assessment battery, supplemented by other assessments in the Screening Questionnaire.
To implement the database, I employed SQLite, specifically leveraging sqlite3 within Python. To ensure accurate data entry, I utilized DB Browser for SQLite to visualize the database. For those interested in learning SQL, numerous resources are available, including a Coursera course titled "Python for Everybody," which I found particularly helpful in practicing with my own datasets.
While I cannot publicly share the participant data due to privacy concerns, the script for constructing the database can be accessed on my GitHub repository. Currently, the database encompasses a single study, but plans are in place to expand it to include multiple studies and additional data points.
Conclusions: Embracing Database Management
I am optimistic about the potential benefits this database will provide for my colleagues and me, and I eagerly anticipate the new insights we can uncover through its use. Finally, if you doubt the value of a relational database in your work, I encourage you to reconsider. Effective database management is crucial across all institutions and can significantly enhance both the quality of your research and your overall workflow.
The first video, "5 Habits That Made Me Become A Data Scientist," provides valuable insights into developing skills essential for success in the field of data science.
The second video, "We Took On a Tough SQL Interview Question! | Data Scientist Prep (Intermediate Level)," presents a challenging SQL interview scenario, helping viewers enhance their problem-solving skills in data science.