Unlocking the Power of Transfer Learning with MobileNet-V2
Written on
Chapter 1: Introduction to Transfer Learning
In this article, we will explore one of the fundamental methods for training deep learning models: Transfer Learning. This technique enables us to develop high-performing deep learning models more swiftly and with improved accuracy by leveraging models that have already been trained.
For a deeper understanding, continue reading about Transfer Learning.
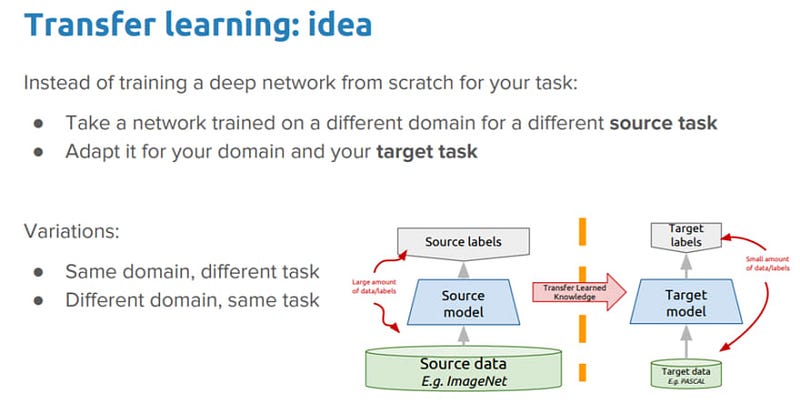
Section 1.1: What is Transfer Learning?
Transfer learning involves utilizing a model that has been pre-trained on a sufficiently large and diverse dataset, making it adaptable for various applications. This allows us to use these pre-trained models without the need for extensive training on a large dataset.
Subsection 1.1.1: The Core Concept of Transfer Learning
General Workflow for Implementing a Pre-trained Model:
- Analyze and comprehend the data.
- Create an input pipeline for the model.
- Load the pre-trained model along with its weights.
- Add classification layers on top.
- Train the model using a GPU.
- Assess the outcomes.

Section 1.2: Benefits of Pre-Trained Models for Feature Extraction
When dealing with a smaller dataset, we can leverage features extracted by a model that has been trained on a larger dataset within the same domain. This process involves initiating the pre-trained model and appending a fully connected classifier on top. The pre-trained model remains unchanged during training, with only the classifier's weights being updated. This strategy enhances the model's accuracy, even when working with limited data and fewer computational resources.
Chapter 2: Practical Implementation of Transfer Learning
For hands-on experience, you can find the Jupyter Notebook containing the Transfer Learning code here. Review my comments within the code for additional insights.
We utilized the MobileNet V2 model for our training purposes.
Video Description: This video demonstrates how to implement Transfer Learning using MobileNet-V2 for image classification, showcasing the practical aspects of the technique.
MobileNet V2, developed by Google, is trained on the ImageNet dataset, which contains 1.4 million images across 1,000 classes.

Section 2.1: Utilizing the Bottleneck Layer for Feature Extraction
In the cats_vs_dogs dataset, we employed the final layer preceding the flatten operation for feature extraction, known as the "bottleneck layer." This layer preserves more general features compared to the top layer. We configured the model with include_top=False to ensure we load a version without the classification layers at the top.
Model Performance:
Initially, the model achieved an accuracy of 0.54 and a loss of 0.63 on the validation set before training. After training on the training set, the model's accuracy improved to 0.9501 with a loss of 0.1020.
Visit us at DataDrivenInvestor.com for more insights.
Subscribe to DDIntel for updates, and join our creator ecosystem.
Video Description: This video covers the process of customizing MobileNetV2 through transfer learning using Keras and Python, providing viewers with practical coding examples and insights into model customization.